中文乱码中日韩乱码区别之详细分析与全面探讨
在当今数字化的时代,信息的交流和传递变得无比便捷,但同时也伴随着一些问题,其中乱码现象就是一个较为常见且令人困扰的情况。尤其是在涉及中文、日文和韩文的文本处理中,乱码的出现往往会影响信息的准确理解和有效传递。将对中文乱码与日、韩乱码的区别进行详细的分析和全面的探讨。
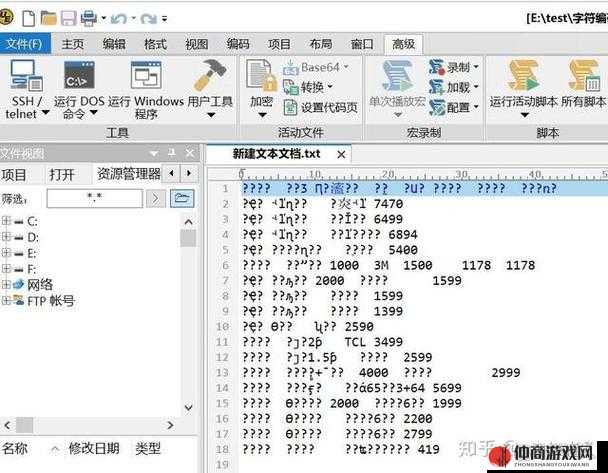
我们需要了解中文、日文和韩文在字符编码方面的特点。中文主要使用的字符编码有 GB2312、GBK、UTF-8 等。GB2312 是最早的中文编码标准,包含了常用的简体汉字;GBK 在 GB2312 的基础上进行了扩展,收录了更多的汉字和符号;UTF-8 则是一种通用性很强的编码方式,能够处理多种语言的字符。
日文的字符编码常见的有 Shift_JIS、EUC-JP 和 UTF-8 等。Shift_JIS 主要用于日文的编码,但其对一些特殊字符的支持有限;EUC-JP 则在处理日文方面更加全面;UTF-8 同样适用于日文的编码。
韩文的主要编码有 EUC-KR 和 UTF-8 等。EUC-KR 专门用于韩文的编码,而 UTF-8 作为通用编码也被广泛使用。
在实际应用中,中文乱码与日、韩乱码的区别主要体现在以下几个方面。
其一,字符集的范围不同。中文的字符集相对较为庞大,涵盖了丰富的汉字、标点符号以及一些特殊的字符。日文除了平假名、片假名和汉字外,还有一些独特的符号和发音标记。韩文则有独特的元音和辅音字符组合。
其二,编码方式的兼容性存在差异。某些软件或系统可能对中文的某种编码支持较好,但对日文或韩文的相应编码支持不足,从而导致乱码的出现。
其三,语言结构和语法规则的不同也会影响乱码的表现形式。中文的语法结构和词汇组合方式与日、韩语言有明显区别,这在乱码中可能会有所反映。
为了避免中文乱码与日、韩乱码的出现,我们可以采取以下一些措施:
一是在进行文本处理和传输时,尽量使用通用的编码格式,如 UTF-8,以确保不同语言的兼容性。
二是在开发软件和系统时,要充分考虑多语言的支持,进行全面的编码测试和优化。
三是对于用户来说,要注意设置正确的语言和编码选项,以保证能够正确显示和处理各种语言的文本。
问题与解答:
问题 1:如果在一个系统中同时处理中文、日文和韩文的文本,应该优先选择哪种编码方式?
答:建议优先选择 UTF-8 编码方式,因为它具有良好的通用性和兼容性,能够有效地处理多种语言的字符。
问题 2:当遇到乱码时,如何快速判断是中文乱码还是日、韩乱码?
答:可以通过一些特征字符来初步判断。比如,日文中常见的平假名、片假名,韩文中独特的元音和辅音组合。但这种判断方法并不绝对,还需要结合具体的上下文和字符出现的频率来综合分析。
问题 3:在网页开发中,如何确保页面能够正确显示中文、日文和韩文?
答:在网页的标签中明确指定编码为 UTF-8,并且在服务器端设置正确的响应头信息,同时确保所引用的外部资源(如 CSS、JavaScript 文件)也使用相同的编码。参考文献:
1. 字符编码原理与应用,作者:[作者姓名],出版社:[出版社名称],出版年份:[出版年份]
2. "Analysis of Encoding Differences between Chinese, Japanese and Korean Languages",作者:[作者姓名],期刊:[期刊名称],发表年份:[发表年份]
3. 多语言编码处理实战,作者:[作者姓名],出版社:[出版社名称],出版年份:[出版年份]
4. "The Challenges of Handling Multilingual Text in Digital Systems",作者:[作者姓名],期刊:[期刊名称],发表年份:[发表年份]
5. 中日韩文字编码技术详解,作者:[作者姓名],出版社:[出版社名称],出版年份:[出版年份]